Introduction to AI-Powered Information Extraction Concepts
Introduction
- These days organizations deal with all kinds of content such as documents, video, images and text.
- A common task in these organizations includes extracting key information from the content and store it into databases.
- Following are some of the usecases:
- A manufacturer wants to identify images of the products for defects and anomalies.
- A business wants to extract key data and summaries from invoices, contracts and reports with charts and log them.
- Hours of customer call recordings for quality purposes needs to be transcribed, summarized and analyzed for sentiment.
- Important moments in a large volume of video streaming, needs to be tagged with metadata.
- Manually processing such content can be slow and potentially error-prone.
- AI-powered information extraction encompasses capabilities that extract meaning from content.
Overview
- AI-powered information extraction and analysis helps organizations gain actionable insights from data.
- These insights can come from structured or unstructured content.
- Structured content is the content stored in consistent format like invoices, tax forms, tables etc; while, unstructured content includes emails, audio recordings, images and videos which are not in a predefined format.
Information extraction processes
Step 1: Source Identification
- Determining where the information resides and if it needs to be digitalized.
Step 2: Extraction
- Leverages many techniques based on ML to understand the extract data from digitized content.
Step 3: Transformation & Structuring
- Extracted data is transformed into structured formats like JSON and tables.
Step 4: Storage & Integration
- The processed data is then stored in databases, data lakes, or analytics platforms for further use.
Understand the extraction of data from images
- AI-powered information extraction replaces the need to manually inspect each piece of content for insights.
- Computer vision can extract insights from images.
- Computer vision is made possible by machine learning models that are trained to recognize features based on large volumes of existing images.
- Machine learning models process images by transforming the images into numerical information.
- At its core, vision models perform calculations on the numerical information, which result in predictions of what is in the images.

- OCR helps computers recognized text elements in an image.
- It is the foundation of preprocessing text in images.
- It uses ML models that are trained to recognize individual shapes as letters, numerals or other elements of text.
- Early work on implementing this capability was done by postal services to support automatic sorting of mail based on postal code.
- Now we have models that can detect printed or handwritten text in an image and digitize it.
Understand the extraction of data from forms
-
Forms and documents have text with semantic meaning.
-
Semantic meaning refers to the intended meaning of words, phrases or symbols in a given content.
-
It focuses on what the word or sentence actually conveys.
-
As an extension of OCR, Document Intelligence describes AI capabilities that processes text and attach semantic meaning to the extracted text.
-
Consider an organization that needs to process a large numbers or receipts for accounting purposes.
-
It can use Document Intelligence to digitize the text in scanned image of the receipt using OCR, and extract semantic meaning.
-
The semantic meaning of data in forms can be described in field-value pairs.
- The field name is the key or type of data entry.
- The field description is the definition of what the field name represents.
- The value corresponds with the field name and is the data specific to the content.
-
For example, in an invoice, the fields recognized may include:
- Name, address, and telephone number of the merchant
- Date and time of the purchase
- Name, quantity, and price of each item purchased
- Total, subtotals, and tax values
-
The data in forms is recognized with bounding boxes.

-
For example, the address information in on the receipt is saved as a field name,
addressand a value,123 Main Streetwith coordinates[4.1, 2.2], [4.3, 2.2], [4.3, 2.4], [4.1, 2.4]. -
Machine learning models can interpret the data in a document or form because they are trained to recognize patterns in bounding box coordinate locations.
-
The results of data extraction are associated with confidence levels for each field and data pair.
-
This confidence level is a percentage between 0 and 1, indicating the likely level of accuracy.
-
Data extracted with a high confidence score (closer to 1) could be relied on more confidently to actually represent what is in the original content.
Understand multimodal data extraction
- AI-powered information extraction techniques can be combined to perform data extraction on multiple types of content, from documents to video and audio.
- Multimodal data extraction can help with digital asset management, workflow automation, generating further insights, and more.
- The orchestration of extraction techniques can include vision and document intelligence, and others including:
Natural language processing
- It can be used to find key phrases, entities, sentiment, etc. in written or spoken language.
Speech recognition
- It takes the spoken word and converts it into data that can be processed - often by transcribing it into text.
- The spoken words can be in the form of a recorded voice in an audio file, or live audio from a microphone.
Generative AI
-
It can add to the data extraction process by allowing users to identify their own fields and field descriptions.
-
It can be particularly useful when dealing with unstructured content.
-
One example is the user-added field of "summary".
-
The value associated with the field must be generated based on the data in the content.
-
The content processing pipeline for multimodal information extraction can include layers of these extraction techniques.
-
One example of the pipeline's output is structured insights and additional generated content.
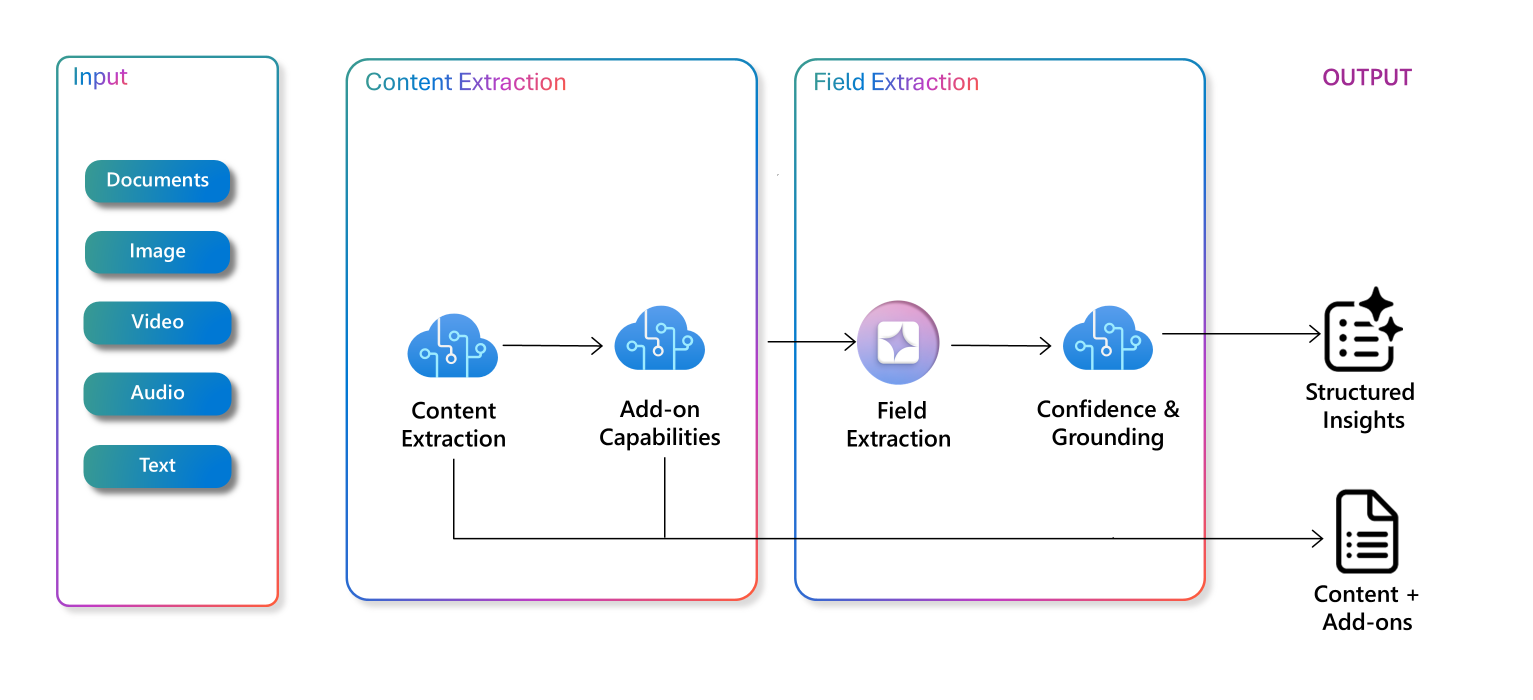
Understand data extraction for knowledge mining
- Knowledge mining solutions are tools or systems that help automatically pull out useful information from huge amounts of data, especially when that data is messy or unstructured (like emails, PDFs, images, or scanned forms).
- At the heart of knowledge mining is search.
- Search is letting users type in a question or keyword and get the most relevant answers from a giant pile of data.
- Now, with AI, It can do much more than traditional keyword search:
- AI can understand context, relationships, and meaning.
- It can extract names, dates, topics, emotions, and more.
Step 1: Document Cracking
- In AI-powered information extraction for search, content first moves through Document cracking.
- Document cracking describes opening document formats like PDFs to extract the contents as ASCII text for analysis and indexing.
Step 2: AI Enrichment
- The contents then move through AI enrichment, which implements AI on your original content to extract more information. Examples of AI enrichment include adding captions to a photo and evaluating text sentiment.
Step 3: Knowledge Store
- AI enriched content can be sent to a knowledge store, which persists the content for independent analysis or downstream processing.
Step 4: Search Index
- The resulting data is serialized as JSON data which populates the search index.
- The populated search index can be explored through queries.
- When users make a search query such as "coffee", the search engine looks for that information in the search index.
- A search index has a structure similar to a table, known as the index schema.
- A typical search index schema contains fields, the field's data type (such as string), and field attributes.
- The fields store searchable text, and the field attributes allow for actions such as filtering and sorting.
- Below is an example of a search index schema:

- A result is a search solution which typically includes the following components:
| Component | Function |
|---|---|
| API Layer | Accepts user queries and routes them to the search engine. |
| Query Processor | Parses and interprets the query. |
| Search Strategies | Determines how to search—e.g., keyword, semantic, vector, or hybrid. |
| Execution Engine | Executes the query across the search index. AI-powered information extraction adds to the data that is searchable. |
| Result Aggregator | Combines results from multiple sources into a unified list. |
| Ranking Engine | Sorts results based on relevance, freshness, popularity, or AI signals. |
| Response Formatter | Formats the results for display in the user interface. |